
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- 성능
- 톰캣
- 자바
- Eclipse
- JEUS
- Book
- 튜닝
- 이클립스
- Excel
- 함수
- 도서
- DB
- 마이플랫폼
- 태그를 입력해 주세요.
- oracle
- Tomcat
- 엑셀
- 한글
- error
- 회계
- MIP
- 오류
- java
- JavaScript
- 오라클
- Report Designer
- miplatform
- 기타소득
- 에러
- 데이터베이스
Archives
- Today
- Total
어느 가을날의 전환점
ORACLE|Table Function 과 Pipeline Table Function (테이블 함수) 본문
Table Function 과 Pipeline Table Function 의 차이점
Table Function
Pipeline Table Function
한 Row씩 처리하므로 바로 결과 값들이 출력되기 시작
Table Function은 전체 데이터 처리를 수행하지만 Pipelined Table Function은 부분 범위 처리를 수행한다는 것을 확인할 수 있다.
Table function 은 전체 데이터가 처리된 이후에 결과가 조회가 되며, Pipeline Table function 은 row 단위로 처리가 된부분에 대해서는 조회가 되어 노출이 되는것이다...
하지만... Application 에서 사용할때에는 위의 같은 pipeline Table function 을 사용하게되면...
응답이 바로바로 와서 application 단에서 혼돈이 있지 않는가 의문이 든다.
일전에 pipeline table function 을 사용하던 부분이 있었는데, application 에서 사용하면 oracle 오류가 발생해서 한참 찾다가 pipeline 을 삭제했더니 문제없이 해결이 된적이 있다.
application 에서 바로 사용하는 경우에는 좀 문제가 있을수 있으니 좀더 확인한 후에 사용을 해야할것이다..
Table Function
값을 리턴할 때 단순히 string 형태로 return 하는 것이 아니고 table 형태로 return을 함.
Pipeline Table Function
create or replace function pipeline_func(strt int, end int)
return table_type1
pipelined ==> Table Function 과 pipeline Table Function 문법 차이점..
is
.......
return table_type1
pipelined ==> Table Function 과 pipeline Table Function 문법 차이점..
is
.......
Table Function은 전체 데이터 처리를 수행하지만 Pipelined Table Function은 부분 범위 처리를 수행한다는 것을 확인할 수 있다.
Table function 은 전체 데이터가 처리된 이후에 결과가 조회가 되며, Pipeline Table function 은 row 단위로 처리가 된부분에 대해서는 조회가 되어 노출이 되는것이다...
하지만... Application 에서 사용할때에는 위의 같은 pipeline Table function 을 사용하게되면...
응답이 바로바로 와서 application 단에서 혼돈이 있지 않는가 의문이 든다.
일전에 pipeline table function 을 사용하던 부분이 있었는데, application 에서 사용하면 oracle 오류가 발생해서 한참 찾다가 pipeline 을 삭제했더니 문제없이 해결이 된적이 있다.
application 에서 바로 사용하는 경우에는 좀 문제가 있을수 있으니 좀더 확인한 후에 사용을 해야할것이다..
"PL/SQL 의 기능중에 커서(Select 문)을 인자로 받아서 복잡한 계산을 수행후 결과를 집합으로 RETURN 하는 기능이 있습니까?"
이런 경우 필자는 예외없이 Pipelined Table Function 을 권장한다.(단 버젼이 8i 이상이라면)
Pipelined Table Function 를 사용하여야 하는 이유는 4가지 이다.
1.PL/SQL 의 유일한 단점은 부분범위처리가 안된다는 것이다.
즉 모든처리가 끝나야만 결과가 화면에 Return 된다는 것이다.
Pipelined Table Function 을 사용하면 이런단점을 극복할수 있다.
당연히 조회화면등에서 성능이 개선된다.
이개념을 이용하려면 Pipe Row 기능을 이해해야한다.
Pipe Row 기능은 9i 이상에서만 사용가능하며 8i 라면 Table Function 만 사용이 가능하므로
부분범위 처리가 불가능하다.
2.SQL 이 길어서 A4 용지 기준으로 1 ~ 2 페이지가 넘어가는 경우가 있다.
이런경우 모니터링을 해보면 엄청난양의 SQL 이 네트웍을 타고 DBMS 에 전달 된다.
이런 SQL 들이 여러명이 사용하고 자주 사용된다면 네트웍의 부하가 상당하므로
Pipelined Table Function 을 사용하면 SQL 이 1~2줄로 줄어들므로 네트웍 튜닝이 가능해진다.
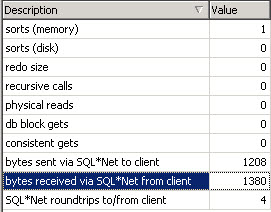
이부분의 모니터링은 AutoTrace 의 "bytes received via SQL*Net from client" 부분을
살펴보면 된다.
아래그림의 선택된 부분이 문제의 네트웍 전송량이다.
아래를 결과를 보면 DB 서버로 부터 결과를 전송받은 양보다 Client 에서 SQL 문을
DB 서버로 전송한 데이터양이 더크다.
이런일이 많을경우 전체적인 시스템이 느려지게 되는데 왜느린지 알수가 없는경우가 많다.
왜냐하면 시스템 Wait Event 모니터링을 해도 이런종류의 Event 는 대부분의 DBA 들이 Idle Event 로 생각하기 때문이다.
현재 시중에 있는 일반적인 Wait Event 책이 사람들을 그렇게 생각하도록 만든다.
이런경우는 Idle Event 로 생각하면 안된다.
대부분의 그런종류의 책들은 Event 들의 원인 + 조치방법으로 되어 있다.
하지만 이런경우 해법을 찾을수 있는 책은 거의없다.
Rechmond See 의 "Oracle Wait Interface" 라는 책을 보면 SQL 에 문제가 있거나 네트웍 성능이 문제라고 되어 있지만 그렇지 않은 경우가 대부분이다.
왜냐하면 SQL 이 길다고 그 SQL 이 잘못된것은 아니며, 대부분 네트웍을 점검해봐도 정상이기 때문이다.
유일하게 욱짜님의 책에 "실행횟수가 많은경우 DBMS CALL 을 줄이고 PL/SQL 로 처리하라" 고 되어있다.
하지만 SQL이 조회화면의 SELECT 문일 경우라면?
이경우는 DBMS CALL 을 줄일수도 없고 DML(INSERT/UPDATE/DELETE) 처럼 PL/SQL로 바꿔서 Array Processing 으로 처리할수도 없는 노릇이다.
이때의 Solution 은 단한가지이다.
SQL 이 Select 이면 아래 예제에서 사용될 Table 함수나 Ref 커서를 사용한 Procedure 를 이용하면 된다.
위의 기능들은 대부분의 사람들이 알고 있지만 위의 기능을 SQL*Net message from client Event 의 해법으로 생각하는 사람들이 거의없는 이유는 무었일까?
3.SQL 을 인자로 던질수 있으며 결과가 Multi Column + Multi Row 로 Return 될수 있다는 점이다.
4.모듈로써 공유가 가능하다는점
이것이 안된다면 복잡한 계산을 해야하는 모든곳에서 기능을 구현하여야만 한다.
필자는 1,2번이 맘에 들지만 개발자들은 3,4 번을 가장 맘에 들어한다.(아마도 입장 차이인가 보다.^^)
아래의 Script 를 보자.
Script 상의 오른쪽의 주석을 참조하기 바란다.(Oracle 의 HR 스키마에서 테스트 하면됨)
1.먼저 패키지 Header 를 만든다.
2.패키지 Body 를 만든다.
위 함수의 Logic 을 설명하면 함수는 사원 성명에 대하여 1줄 return 하고
사원의 번화번호및 email 에 대하여 또 한줄 return 한다.
위 함수의 특징은 Pipe Row 에 있다.
Pipe Row 를 명시하면 Loop 내에서 결과를 즉시 Return 한다.
즉 모든 Loop 가 끝나길 기다릴 필요가 없는것이다.
물론 전체를 처리해야만 하는경우는 Pipe Row 를 명시하지 않으면 되고 Bulk Collect 기능을 권장한다.
이때는 함수 선언시 PIPELINED 를 명시하면 안되며 RETURN 시의 변수도 지정해야한다.
Pipe Row 와 PIPELINED 는 항상 Pair 로 움직여야 한다.
3.만들어진 Pipelined Table Function 를 사용한다.
4.결과

결론 : Pipelined Table Function 함수는 부분범위 처리가 가능하며 결과를 Row Set 으로 Return 할수있다.
이기능은 SQL*Net message from client Event 과다현상의 훌륭한 해결책이다.
이기능을 잘 사용하면 다양한 분야에 활용할수 있다.
Reference : 10g PL/SQL User's Guide and Reference 의 Tuning PL/SQL Applications for Performance 부분.
편집후기 :
Table 함수와 테이블간의 조인이 가능한지 질문이 들어왔다.
당연히 된다.
한가지 주의할점은 조인절이 따로 필요없고 Table 함수의 인자로 컬럼의 Value 가 필요하다는 것이다.
아래에 예제를 참조하라.
아래 예제에서 CAST 함수를 쓴이유는 버젼이 8i 이기 때문이다. (9i 이상은 필요없음)
select X.SUBCON_CD,
X.SUBCON_NM,
X.SUBCON_CONTI_CLS,
X.SUBCON_DESC,
Y.COM_CLS4_NM,
Y.COM_CLS4_ALIAS_CD,
Y.COM_CLS2,
Y.COM_CLS4_DESC
From TOLC_S_SUBCONTINENT X,
TABLE( CAST( COMM.get_com_info(X.SUBCON_CONTI_CLS) AS COMLIST_T) ) Y
이런 경우 필자는 예외없이 Pipelined Table Function 을 권장한다.(단 버젼이 8i 이상이라면)
Pipelined Table Function 를 사용하여야 하는 이유는 4가지 이다.
1.PL/SQL 의 유일한 단점은 부분범위처리가 안된다는 것이다.
즉 모든처리가 끝나야만 결과가 화면에 Return 된다는 것이다.
Pipelined Table Function 을 사용하면 이런단점을 극복할수 있다.
당연히 조회화면등에서 성능이 개선된다.
이개념을 이용하려면 Pipe Row 기능을 이해해야한다.
Pipe Row 기능은 9i 이상에서만 사용가능하며 8i 라면 Table Function 만 사용이 가능하므로
부분범위 처리가 불가능하다.
2.SQL 이 길어서 A4 용지 기준으로 1 ~ 2 페이지가 넘어가는 경우가 있다.
이런경우 모니터링을 해보면 엄청난양의 SQL 이 네트웍을 타고 DBMS 에 전달 된다.
이런 SQL 들이 여러명이 사용하고 자주 사용된다면 네트웍의 부하가 상당하므로
Pipelined Table Function 을 사용하면 SQL 이 1~2줄로 줄어들므로 네트웍 튜닝이 가능해진다.
이부분의 모니터링은 AutoTrace 의 "bytes received via SQL*Net from client" 부분을
살펴보면 된다.
아래그림의 선택된 부분이 문제의 네트웍 전송량이다.
아래를 결과를 보면 DB 서버로 부터 결과를 전송받은 양보다 Client 에서 SQL 문을
DB 서버로 전송한 데이터양이 더크다.
이런일이 많을경우 전체적인 시스템이 느려지게 되는데 왜느린지 알수가 없는경우가 많다.
왜냐하면 시스템 Wait Event 모니터링을 해도 이런종류의 Event 는 대부분의 DBA 들이 Idle Event 로 생각하기 때문이다.
현재 시중에 있는 일반적인 Wait Event 책이 사람들을 그렇게 생각하도록 만든다.
이런경우는 Idle Event 로 생각하면 안된다.
대부분의 그런종류의 책들은 Event 들의 원인 + 조치방법으로 되어 있다.
하지만 이런경우 해법을 찾을수 있는 책은 거의없다.
Rechmond See 의 "Oracle Wait Interface" 라는 책을 보면 SQL 에 문제가 있거나 네트웍 성능이 문제라고 되어 있지만 그렇지 않은 경우가 대부분이다.
왜냐하면 SQL 이 길다고 그 SQL 이 잘못된것은 아니며, 대부분 네트웍을 점검해봐도 정상이기 때문이다.
유일하게 욱짜님의 책에 "실행횟수가 많은경우 DBMS CALL 을 줄이고 PL/SQL 로 처리하라" 고 되어있다.
하지만 SQL이 조회화면의 SELECT 문일 경우라면?
이경우는 DBMS CALL 을 줄일수도 없고 DML(INSERT/UPDATE/DELETE) 처럼 PL/SQL로 바꿔서 Array Processing 으로 처리할수도 없는 노릇이다.
이때의 Solution 은 단한가지이다.
SQL 이 Select 이면 아래 예제에서 사용될 Table 함수나 Ref 커서를 사용한 Procedure 를 이용하면 된다.
위의 기능들은 대부분의 사람들이 알고 있지만 위의 기능을 SQL*Net message from client Event 의 해법으로 생각하는 사람들이 거의없는 이유는 무었일까?
3.SQL 을 인자로 던질수 있으며 결과가 Multi Column + Multi Row 로 Return 될수 있다는 점이다.
4.모듈로써 공유가 가능하다는점
이것이 안된다면 복잡한 계산을 해야하는 모든곳에서 기능을 구현하여야만 한다.
필자는 1,2번이 맘에 들지만 개발자들은 3,4 번을 가장 맘에 들어한다.(아마도 입장 차이인가 보다.^^)
아래의 Script 를 보자.
Script 상의 오른쪽의 주석을 참조하기 바란다.(Oracle 의 HR 스키마에서 테스트 하면됨)
1.먼저 패키지 Header 를 만든다.
CREATE OR REPLACE PACKAGE refcur_pkg IS
TYPE refcur_t IS REF CURSOR -- cursor type 을 선언한다.
RETURN employees%ROWTYPE;
TYPE outrec_typ IS RECORD ( -- structure type을 선언한다.
var_num employees.employee_id%type,
var_char1 VARCHAR2(30),
var_char2 VARCHAR2(30) );
TYPE outrecset IS TABLE OF outrec_typ; -- 위에서 선언한 structure 를 배열로 type 으로 선언한다
FUNCTION f_trans(p refcur_t) -- 커서를 인자로 받아서 Structure 배열을 Return 하는 함수를 선언한다.
RETURN outrecset PIPELINED; -- 위에서 선언한 Structure 배열을 사용함.
-- 반드시 PIPELINED를 명시해야함.
END refcur_pkg;
/
TYPE refcur_t IS REF CURSOR -- cursor type 을 선언한다.
RETURN employees%ROWTYPE;
TYPE outrec_typ IS RECORD ( -- structure type을 선언한다.
var_num employees.employee_id%type,
var_char1 VARCHAR2(30),
var_char2 VARCHAR2(30) );
TYPE outrecset IS TABLE OF outrec_typ; -- 위에서 선언한 structure 를 배열로 type 으로 선언한다
FUNCTION f_trans(p refcur_t) -- 커서를 인자로 받아서 Structure 배열을 Return 하는 함수를 선언한다.
RETURN outrecset PIPELINED; -- 위에서 선언한 Structure 배열을 사용함.
-- 반드시 PIPELINED를 명시해야함.
END refcur_pkg;
/
2.패키지 Body 를 만든다.
CREATE OR REPLACE PACKAGE BODY refcur_pkg IS
FUNCTION f_trans(p refcur_t)
RETURN outrecset PIPELINED IS -- Structure 배열을 Return 하는 함수임.
out_rec outrec_typ; -- PACKAGE Header 에서 선언한 structute type 을 변수로 선언한다.
in_rec p%ROWTYPE; -- p cursor 네의 의 모든컬럼을 변수로 선언한다.
BEGIN
LOOP
FETCH p INTO in_rec;
EXIT WHEN p%NOTFOUND;
-- first row
out_rec.var_num := in_rec.employee_id;
out_rec.var_char1 := in_rec.first_name;
out_rec.var_char2 := in_rec.last_name;
PIPE ROW(out_rec); --> employee_id, first_name, last_name 으로 1 row 를 즉시 return 한다.
-- second row
out_rec.var_char1 := in_rec.email;
out_rec.var_char2 := in_rec.phone_number;
PIPE ROW(out_rec); --> employee_id, email, phone_number 으로 1 row 를 즉시 return 한다.
END LOOP;
CLOSE p;
RETURN; -- return 하는 변수를 지정하지 않는다.(LOOP 내에서 모두 Return 되었기 때문이다.)
END;
END refcur_pkg;
/
FUNCTION f_trans(p refcur_t)
RETURN outrecset PIPELINED IS -- Structure 배열을 Return 하는 함수임.
out_rec outrec_typ; -- PACKAGE Header 에서 선언한 structute type 을 변수로 선언한다.
in_rec p%ROWTYPE; -- p cursor 네의 의 모든컬럼을 변수로 선언한다.
BEGIN
LOOP
FETCH p INTO in_rec;
EXIT WHEN p%NOTFOUND;
-- first row
out_rec.var_num := in_rec.employee_id;
out_rec.var_char1 := in_rec.first_name;
out_rec.var_char2 := in_rec.last_name;
PIPE ROW(out_rec); --> employee_id, first_name, last_name 으로 1 row 를 즉시 return 한다.
-- second row
out_rec.var_char1 := in_rec.email;
out_rec.var_char2 := in_rec.phone_number;
PIPE ROW(out_rec); --> employee_id, email, phone_number 으로 1 row 를 즉시 return 한다.
END LOOP;
CLOSE p;
RETURN; -- return 하는 변수를 지정하지 않는다.(LOOP 내에서 모두 Return 되었기 때문이다.)
END;
END refcur_pkg;
/
위 함수의 Logic 을 설명하면 함수는 사원 성명에 대하여 1줄 return 하고
사원의 번화번호및 email 에 대하여 또 한줄 return 한다.
위 함수의 특징은 Pipe Row 에 있다.
Pipe Row 를 명시하면 Loop 내에서 결과를 즉시 Return 한다.
즉 모든 Loop 가 끝나길 기다릴 필요가 없는것이다.
물론 전체를 처리해야만 하는경우는 Pipe Row 를 명시하지 않으면 되고 Bulk Collect 기능을 권장한다.
이때는 함수 선언시 PIPELINED 를 명시하면 안되며 RETURN 시의 변수도 지정해야한다.
Pipe Row 와 PIPELINED 는 항상 Pair 로 움직여야 한다.
3.만들어진 Pipelined Table Function 를 사용한다.
SELECT *
FROM TABLE(refcur_pkg.f_trans(CURSOR(SELECT *
FROM employees
WHERE department_id = 60) ) );
FROM TABLE(refcur_pkg.f_trans(CURSOR(SELECT *
FROM employees
WHERE department_id = 60) ) );
4.결과
결론 : Pipelined Table Function 함수는 부분범위 처리가 가능하며 결과를 Row Set 으로 Return 할수있다.
이기능은 SQL*Net message from client Event 과다현상의 훌륭한 해결책이다.
이기능을 잘 사용하면 다양한 분야에 활용할수 있다.
Reference : 10g PL/SQL User's Guide and Reference 의 Tuning PL/SQL Applications for Performance 부분.
편집후기 :
Table 함수와 테이블간의 조인이 가능한지 질문이 들어왔다.
당연히 된다.
한가지 주의할점은 조인절이 따로 필요없고 Table 함수의 인자로 컬럼의 Value 가 필요하다는 것이다.
아래에 예제를 참조하라.
아래 예제에서 CAST 함수를 쓴이유는 버젼이 8i 이기 때문이다. (9i 이상은 필요없음)
select X.SUBCON_CD,
X.SUBCON_NM,
X.SUBCON_CONTI_CLS,
X.SUBCON_DESC,
Y.COM_CLS4_NM,
Y.COM_CLS4_ALIAS_CD,
Y.COM_CLS2,
Y.COM_CLS4_DESC
From TOLC_S_SUBCONTINENT X,
TABLE( CAST( COMM.get_com_info(X.SUBCON_CONTI_CLS) AS COMLIST_T) ) Y
# 출처 및 참고자료
3) Using Pipelined and Parallel Table Functions
http://download.oracle.com/docs/cd/B14117_01/appdev.101/b10800/dcitblfns.htm
http://download.oracle.com/docs/cd/B14117_01/appdev.101/b10800/dcitblfns.htm
'Database > Oracle' 카테고리의 다른 글
| ORACLE|오라클 System Tables (0) | 2010.11.24 |
|---|---|
| ORACLE|테이블(Table) 생성 및 데이터 복사 방법 (0) | 2010.08.17 |
| ORACLE|JOIN 성능 - 일반적으로 크기가 작은 테이블이 먼저 드라이빙 되는 것이 빠르다. (0) | 2010.07.28 |
| ORACLE|조인(Join) - Nested Loops, Sort Merge, Hash (0) | 2010.07.28 |
| ORACLE|인덱스(Index) (0) | 2010.07.21 |
Comments